Видео с ютуба Metal Inference Engine

The Inference Engine: Building AI That Performs at Scale | theCUBE + NYSE Wired: AI Factories

Building an LLM Inference Engine on Apple Silicon - Part 1: How GPT Actually Works

AI Tech Talk from Plumerai: Demo of the world’s fastest inference engine for Arm Cortex-M

Nvidia CUDA vs Apple Metal for AI Work

Почему делать логические выводы сложно...

Механизмы вывода (Часть 1)

3000 Tokens/Sec - Building a high throughput LLM inference engine

DwarfStar -- DeepSeek 4 Flash local inference engine for Metal and CUDA

Освоение vLLM на практическом примере

antirez 'chơi lớn' với AI local: Đám mây sắp vô dụng?
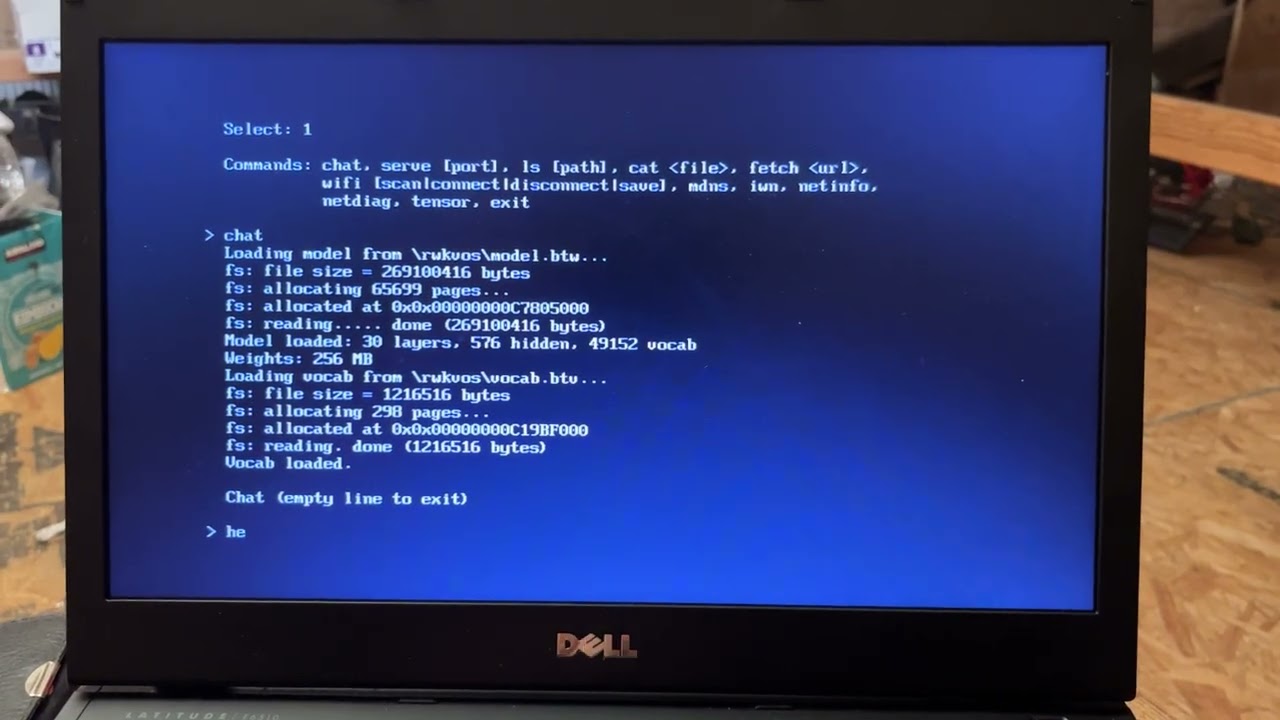
Bare-Metal AI: Booting Directly Into LLM Inference ‚ No OS, No Kernel (Dell E6510)

Освоение оптимизации вывода LLM: от теории до экономически эффективного внедрения: Марк Мойу

ds4: antirez's New Inference Engine — 7.1k Stars in 4 Days

Скрытое оружие для вывода ИИ, которое упустил каждый инженер

Docker Model Runner: vLLM Support for Apple Silicon Metal

Your local LLM is 10x slower than it should be

What Is An AI Inference Engine And How Does It Work? - AI and Machine Learning Explained

AI Inference: The Secret to AI's Superpowers

Inference: AI’s Hidden Engine

Faster LLMs: Accelerate Inference with Speculative Decoding